Dynamo: Amazon's Highly Available Key-value Store
What is this paper about?
This is a review of the famous 2007 paper from Amazon that introduced Dynamo, a revolutionary database system that powers many of Amazon's core services. This paper is significant because it popularized key concepts in distributed systems like eventual consistency, consistent hashing, and vector clocks. It also inspired a wave of NoSQL databases including Cassandra, Riak, and Voldemort.
Important note: This paper describes the internal "Dynamo" system, which is different from AWS DynamoDB (the publicly available service launched in 2012, though inspired by these ideas).
Abstract
Reliability at massive scale is one of the biggest challenges we face at Amazon.com, one of the largest e-commerce operations in the world; even the slightest outage has significant financial consequences and impacts customer trust. The Amazon.com platform, which provides services for many web sites worldwide, is implemented on top of an infrastructure of tens of thousands of servers and network components located in many data centers around the world. At this scale, small and large components fail continuously and the way persistent state is managed in the face of these failures drives the reliability and scalability of the software systems. This paper presents the design and implementation of Dynamo, a highly available key-value storage system that some of Amazon's core services use to provide an "always-on" experience. To achieve this level of availability, Dynamo sacrifices consistency under certain failure scenarios. It makes extensive use of object versioning and application-assisted conflict resolution in a manner that provides a novel interface for developers to use.
In simpler terms: Amazon needed a database that would never go down, even when servers fail. They built Dynamo to be "always-on" for critical services like shopping carts. The tradeoff? Sometimes different servers might temporarily have different versions of the same data (this is called "eventual consistency"). The system cleverly handles these conflicts so customers never lose their shopping cart items.
Notes
Introduction: Why Did Amazon Build Dynamo?
Amazon's platform has extremely strict requirements for performance, reliability, and efficiency. As the platform grows, it needs to scale seamlessly to handle more traffic and data.
The key insight: The reliability and scalability of a system depends on how it manages application state (the data that needs to persist). For example, customers should be able to view and add items to their shopping cart even if:
- Hard disks are failing
- Network connections are unstable
- Entire data centers are experiencing outages
This means Amazon's systems need to treat failures as the normal case, not the exceptional case, without impacting availability or performance.
Why Not Just Use a Traditional Database?
Many of Amazon's services only need simple key-value access to data. Services like:
- Shopping carts
- Customer preferences
- Session management
- Best seller lists
- Product catalogs
For these use cases, traditional relational databases (like MySQL or PostgreSQL) are overkill. They provide complex querying capabilities that aren't needed, require expensive hardware, and typically prioritize consistency over availability. When network issues occur, traditional databases often become unavailable to protect data consistency.
What Makes Dynamo Different?
Dynamo gives application designers flexible control over the tradeoffs between:
- Availability (the system is always accepting requests)
- Consistency (all servers have the same data)
- Cost-effectiveness (runs on commodity hardware)
- Performance (fast response times)
The technical approach: Dynamo combines several well-known distributed systems techniques:
- Consistent hashing: Distributes data evenly across servers and makes it easy to add/remove servers without reshuffling most of the data
- Object versioning: Keeps track of different versions of data to detect conflicts
- Quorum-like technique: Requires a minimum number of servers to agree on reads/writes for consistency
- Gossip protocol: Servers periodically share information with each other to detect failures and maintain membership
- Decentralized design: No master server means no single point of failure; storage nodes can be added or removed without manual intervention
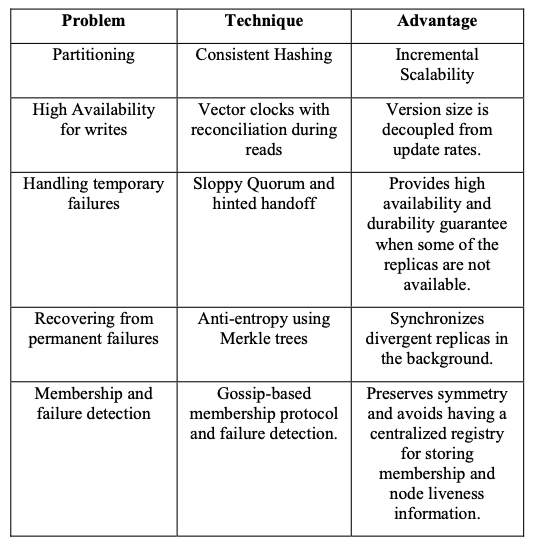
Background: The Problem with Relational Databases
For many common data storage patterns at Amazon, relational databases (RDBMS) are not ideal:
-
Unnecessary complexity: Most services only need to store and retrieve data by a primary key (like a customer ID). They don't need SQL joins, complex queries, or transaction support across multiple tables.
-
High operational cost: The extra features of relational databases require expensive enterprise-grade hardware and highly skilled database administrators.
-
Availability vs. Consistency tradeoff: Traditional database replication typically chooses consistency over availability. This means during network partitions (when servers can't communicate), the database might reject writes to prevent inconsistency. For Amazon's shopping cart, this would mean customers couldn't add items during outages - unacceptable!
Dynamo's solution: A simple key/value interface that is:
- Highly available (always accepts writes)
- Eventually consistent (with a clearly defined consistency window)
- Resource efficient (runs on commodity hardware)
- Easy to scale (just add more nodes)
Each service that uses Dynamo runs its own dedicated Dynamo instances, allowing for service-specific tuning.
Design Assumptions and Constraints
Dynamo was built with specific assumptions that simplified its design:
Functional constraints:
- Single key updates only: Dynamo doesn't support transactions across multiple keys or complex queries. Each operation works on one key at a time.
- No isolation guarantees: Unlike traditional databases, Dynamo doesn't provide transaction isolation (the "I" in ACID).
Operational requirements:
- Tunable performance: Services must be able to configure Dynamo to consistently meet their specific latency and throughput requirements. They control the tradeoffs between performance, cost efficiency, availability, and durability.
- Trusted environment: Dynamo assumes it operates in a non-hostile environment (inside Amazon's data centers), so it doesn't implement authentication or authorization. This simplifies the design.
Service Level Agreement (SLA) example: A typical SLA might be: "Provide a response within 300ms for 99.9% of requests at a peak load of 500 requests per second." Notice how this focuses on the 99.9th percentile, not just averages.
Why Amazon Focuses on the 99.9th Percentile
This is an important insight into how Amazon thinks about performance.
The problem with averages: Most companies measure performance using averages or medians. But these metrics hide the experience of your most important customers.
Example: Imagine a personalization system where customers with long purchase histories require more processing time. These are often your best customers! If you only look at average response times, you'll never notice that these valuable customers are having a slower experience.
Amazon's approach: Measure and optimize for the 99.9th percentile. This means ensuring that even the slowest 0.1% of requests meet acceptable performance standards.
Why not 99.99% or higher? Amazon did a cost-benefit analysis and found that improving performance beyond the 99.9th percentile requires significantly more infrastructure investment for diminishing returns. The 99.9th percentile represents the sweet spot between cost and customer experience.
Key Design Decisions
1. Eventual Consistency: The Core Tradeoff
The approach: Dynamo uses optimistic replication, where changes are allowed to propagate to replicas in the background. This means servers don't wait for confirmation that all replicas have been updated before acknowledging a write.
The problem: Multiple servers might update the same piece of data at the same time, creating conflicts. This raises two questions:
- When should conflicts be resolved?
- Who should resolve them?
Dynamo's choice: It's an "eventually consistent" datastore - all updates reach all replicas eventually, but there might be temporary inconsistencies.
2. "Always Writeable" - Resolving Conflicts on Reads
The key insight: For services like shopping carts, rejecting a customer's update (like adding an item) would create a terrible experience. It's better to always accept the write and deal with conflicts later.
Dynamo's approach: Push conflict resolution complexity to the read side. This ensures writes are never rejected. When you read data, you might get multiple conflicting versions that need to be reconciled.
Example: If you add an item to your cart from your phone and laptop simultaneously (while temporarily disconnected), both writes succeed. When you next view your cart, both items are there because the system merged the conflicting versions.
3. Who Resolves Conflicts?
There are two options:
Option A - Data store resolves conflicts:
- Simple policy like "last write wins" (based on timestamp)
- Limited intelligence - might lose data
- Example: If you added different items from two devices, one might be lost
Option B - Application resolves conflicts (Dynamo's preferred approach):
- The application understands the data semantics
- Can implement smart merging (e.g., union of shopping cart items)
- More work for developers, but better customer experience
- Fallback: Applications can still choose "last write wins" if they want
4. Other Core Principles
- Incremental scalability: Add one server at a time as needed, without downtime
- Symmetry: All nodes have the same responsibilities; no special "master" nodes
- Decentralization: No central coordinator, because centralized control has historically caused outages
- Heterogeneity: Work distribution adapts to server capabilities. You can add powerful new servers without upgrading everything at once
How Dynamo Relates to Other Systems
Dynamo built upon ideas from peer-to-peer (P2P) systems and academic research, while making different tradeoffs. Here's how it compares:
Structured P2P networks:
- Use globally consistent protocols where any node can route queries efficiently to find data
- Dynamo extends these ideas but optimizes for different goals
OceanStore:
- Provides transactional, persistent storage with serialized updates
- Built for untrusted infrastructure (assumes malicious actors)
- Difference: Dynamo operates in trusted datacenters, so it skips security mechanisms for better performance
Bayou:
- A distributed relational database that allows disconnected operations
- Also provides eventual consistency
- Similar philosophy but Dynamo simplifies by dropping the relational model
Antiquity:
- Uses secure logs and Byzantine fault tolerance for data integrity
- Designed to tolerate malicious nodes
- Difference: Dynamo trusts its environment, so it skips these expensive protections
Bigtable (Google's system):
- Stores structured data in a multi-dimensional sorted map
- Supports access by multiple attributes
- Key difference: Bigtable focuses on rich data models; Dynamo focuses on high availability with simple key/value access
Zero-hop DHT (Distributed Hash Table): Traditional DHTs use multi-hop routing: to find data, you ask a node, which points you to another node, etc. Each hop adds latency and variability.
Dynamo's approach: Each node maintains complete routing information to reach any other node directly. This is called a "zero-hop DHT" - no intermediate hops needed. This eliminates variability and keeps 99.9th percentile latency low.
How Dynamo Works: Key Technical Details
Data Placement: Consistent Hashing
Simple approach: Dynamo treats keys and values as opaque byte arrays. It hashes each key (using MD5) to generate a 128-bit identifier, which determines which storage nodes are responsible for that key.
Problem with basic consistent hashing:
- Random node placement leads to uneven data distribution (some nodes get way more data than others)
- Doesn't account for different server capabilities (a powerful server and weak server get the same load)
Solution: Virtual Nodes Instead of placing each physical server at one position on the ring, Dynamo assigns each server to multiple positions (virtual nodes). Benefits:
- Evens out data distribution
- When a node fails, its load is distributed across many other nodes
- Servers with more capacity can have more virtual nodes
Preference lists: For reliability, data is replicated to more than N nodes (where N is the replication factor). The system maintains a "preference list" of nodes responsible for each key.
Version Control: Vector Clocks
The challenge: With concurrent updates, how do you know which version came first?
Vector clocks explained: A vector clock is a list of (node, counter) pairs attached to each data version. Think of it as a version history that tracks which server made each change.
How it works:
- If all counters in version A are ≤ version B's counters, then A is an ancestor of B (B is newer)
- If neither is an ancestor of the other, they're conflicting versions that need reconciliation
Reconciliation types:
- Syntactic reconciliation: System automatically detects that one version supersedes another
- Semantic reconciliation: Application logic merges conflicting versions (e.g., merging shopping cart items)
Shopping cart example:
- Add item A from phone → version [phone:1]
- Add item B from laptop → version [laptop:1]
- These are conflicting versions
- On read, application merges them → cart contains both A and B
- Important: "Add to cart" operations are never lost, but deleted items can sometimes reappear (acceptable tradeoff)
Consistency Protocol: Quorum Systems
Dynamo uses a tunable consistency protocol with three key parameters:
- N: Number of replicas (how many copies of data exist)
- R: Number of nodes that must respond to a read
- W: Number of nodes that must acknowledge a write
Quorum property: When R + W > N, you get guaranteed consistency because read and write sets overlap.
Example configuration (3,2,2):
- N=3: Data is stored on 3 servers
- W=2: Write succeeds after 2 servers acknowledge
- R=2: Read requires responses from 2 servers
- Since 2+2 > 3, at least one server in the read set has the latest data
Keeping Replicas in Sync: Anti-Entropy with Merkle Trees
The problem: Replicas can drift out of sync due to failures or network issues.
Merkle trees: A clever data structure where:
- Leaves contain hashes of individual data items
- Parent nodes contain hashes of their children
- You can compare trees branch by branch to find differences
Benefits:
- Quickly identify which data differs between replicas
- Only transfer the minimal amount of data needed
- Reduces disk reads during synchronization
Membership and Failure Detection
Seed nodes: Special nodes that act as introduction points. All nodes eventually communicate with seeds to learn about cluster membership. This prevents "split brain" scenarios where the cluster accidentally divides into separate groups.
Architecture: Each storage node has three main components:
- Request coordination: Routes requests and manages responses
- Membership and failure detection: Tracks which nodes are alive
- Local persistence engine: Stores data on disk
All components are implemented in Java.
Request Handling: State Machines
Elegant design: Each client request creates a state machine that handles all logic for that single request.
Read operation state machine:
- Send read requests to responsible nodes
- Wait for minimum required responses (R nodes)
- If too few replies within timeout → fail the request
- Otherwise, gather all data versions
- Perform syntactic reconciliation (merge versions the system can understand)
- Return data with a vector clock for the client to use on future writes
Real-World Experiences and Lessons Learned
Amazon deployed Dynamo in production and learned several important lessons:
1. The Consistency-Durability Tradeoff
Low W and R values risk inconsistency: If you set W=1 (write succeeds after just 1 node acknowledges), writes are very fast but risky. The client gets confirmation even though only one node has the data. If that node fails before replicating, data is lost.
Surprising insight: Traditional wisdom says durability (data won't be lost) and availability (system stays up) go hand-in-hand. In Dynamo, they're actually opposing forces. Making the system more available sometimes means accepting temporary data loss risks.
Most common configuration: (N=3, R=2, W=2) This is the sweet spot for most services - good balance of availability, consistency, and durability.
2. Hardware Constraints Matter
Dynamo runs on commodity hardware (cheap, standard servers), not expensive enterprise systems. These servers have much lower I/O throughput, making it challenging to consistently deliver high performance.
Write buffer optimization: To improve performance, Dynamo keeps a small in-memory buffer (just 1000 objects) for recent writes before flushing to disk.
Results: This simple optimization reduced 99.9th percentile latency by 5x during peak traffic!
Tradeoff: If the server crashes before flushing the buffer, those recent writes are lost. Again, trading durability for performance.
3. How Often Do Conflicts Actually Happen?
Amazon measured the shopping cart service for 24 hours:
- 99.94% of requests saw exactly one version (no conflicts)
- 0.00057% saw 2 versions
- 0.00047% saw 3 versions
- 0.00009% saw 4 versions
Takeaway: Conflicts are rare in practice! The complex conflict resolution machinery is needed, but doesn't activate often. Most operations are simple.
4. Client-Driven vs Server-Driven Coordination
Traditional approach: Client sends request to a load balancer, which forwards to a server, which coordinates with other servers.
Alternative: Put the coordination state machine in the client library itself.
Benefits of client-driven approach:
- No load balancer needed (simpler architecture)
- Automatic load distribution since clients choose servers based on the hash ring
- Clients can make smarter decisions about which servers to contact
5. Balancing Foreground vs Background Work
Dynamo has two types of work:
- Foreground tasks: Client requests (highest priority)
- Background tasks: Replica synchronization, Merkle tree rebuilding, etc.
The problem: Background tasks can slow down client requests by competing for resources (disk I/O, CPU, locks).
Solution: Adaptive admission control. The system monitors:
- Disk operation latencies
- Failed database accesses due to lock contention
- Transaction timeouts
- Request queue wait times
Based on these metrics, it dynamically adjusts how much resources background tasks can consume. If client latencies are creeping up, background work is throttled automatically.
Why This Paper Matters
The Dynamo paper is one of the most influential distributed systems papers of the 2000s. Here's why:
Practical impact: Unlike many academic papers, this describes a real production system handling massive scale at Amazon. The lessons are battle-tested, not theoretical.
Popularized key concepts:
- Eventual consistency as a viable production model
- Tunable consistency (choosing your own tradeoffs via N, R, W)
- Practical implementations of vector clocks and consistent hashing
- Application-level conflict resolution
Inspired the NoSQL movement: Systems like Cassandra, Riak, and Voldemort directly borrowed ideas from Dynamo. The paper showed that you could build highly available systems by relaxing consistency guarantees.
Changed how we think about tradeoffs: Before Dynamo, many engineers assumed you needed strong consistency. This paper demonstrated that for many real-world applications (like shopping carts), eventual consistency with smart conflict resolution provides better user experience.
Key Takeaways
-
Availability over consistency: For user-facing services, it's often better to always accept writes and resolve conflicts later than to reject operations during failures.
-
Failures are normal: Design systems that treat failures as the common case, not the exception.
-
Measure tail latencies: The 99.9th percentile matters more than averages when you care about all customers equally.
-
Tunable systems win: Different services need different tradeoffs. Give operators control via parameters like N, R, and W.
-
Simplicity enables scale: By dropping unnecessary features (complex queries, transactions, security in trusted environments), Dynamo achieves better availability and performance.
-
Application-level conflict resolution: The application understands data semantics better than the database, so let it handle conflicts intelligently.
Further Reading
Over the next few Saturdays, I'll be going through some of the foundational papers in Computer Science, and publishing my notes here. This is #18 in this series.